機械の言語能力の獲得を考える

当初、「機械の言語能力の獲得から考える embeddingの共有・蓄積・検索の未来」というテーマでセミナーを開催することを考えていたのですが、長くなりそうなので、セミナーを次の二つに分けることにしました。
- 「機械の言語能力の獲得を考える」
- 「機械と人間が意味を共有する embeddingの世界を考える」
このWebページやYouTubeと並行して、次のblogリストからも関連コンテンツにアクセスできます。https://maruyama097.blogspot.com/2025/12/embedding-blog.html
セミナー概要
今回のセミナーのアプローチ
↑ 見出しクリックでpdfへ
今回のセミナー「機械の言語能力の獲得を考える」は、現代のAI技術の到達点を「機械が言語能力を獲得した」と捉える議論を展開したものです。
機械が新しく獲得した言語能力の中核は、「意味を理解する」能力だと僕は考えています。
今回のセミナーでは、機械の言語能力の獲得の中核を、機械の意味を理解する能力の獲得とする議論を行います。
中心問題は、機械は、どのようにして「意味を理解する」ようになったのか? という問題です。
この問題については、21世紀初めからの「意味の分散表現論」の発展が一つの答えを与えてくれると思っています。
セミナーでは、意味のベクトル表現の発見に始まり、翻訳モデルから大規模言語モデルへの発展へと結実する理論の歴史を振り返ろうと思います。
こうしたアプローチの意味と課題
「言語能力の獲得」→「意味の理解能力の獲得」→「意味の分散表現論の発展」というスキームや、AI技術の発展を分散表現論の歴史で説明するアプローチには、多くのものを捨象しているという問題もあります。
AGI論の功罪
アルトマンは、2035年までに、あらゆる個人が「2025年時点の全人類に匹敵する知的能力」を手に入れることができると予測しています。
https://www.marketingaiinstitute.com/blog/the-ai-show-episode-135
一方、イリヤ・サツケヴァーは、アルトマンとは対照的に、AIがもたらす「実在的なリスク(Existential Risk)」に対して恐怖の念を抱いています。彼は、AIが単なるプログラムではなく、いつか人間を凌駕し、制御不能になる可能性を技術的必然として捉えています。
https://www.ibm.com/think/topics/superalignment
昔、ある人がAIに次のような皮肉な定義を与えたことがあります。「AIとは、まだできていないこと全てである」”Al is whatever hasn’t been done vet.” ( “Gödel, Escher, Bach” D. R. Hofstadter ) AGI (artificial general intelligence)の議論は、それに似ています。
楽観的なAGI論も悲観的なAGI論もあるのですが、AGI論は、AI技術の到達点の評価ではなくまだできていないこと、まだ起きていないことを含んだ未来の予想です。その予想には、傾聴すべき議論も含まれていることもあるのですが、ある場合には、AIにさらなる投資を呼び込むための誇大宣伝に使われています。
言語能力と「知性」
僕は、人間の知性(あるいは、知能)と人間の言語能力を区別しています。人間の知能は複雑な構造を持ち、その最も基本的な構成要素、最も重要な基礎が言語能力なのだと。
親と子も恋人同士の二人も老人ホームの老人もことばを使います。SNSで罵倒し合うのにも、戦争を呼びかけるのにも戦争に反対するのにもことばが必要です。捏造された論文もノーベル賞の対象となる論文も、ことばで書かれています。これらすべては、人間がひとしく言語能力を持ってコミュニケーションできるから可能になっていることです。
言語能力をもつ人間がそうであるように、機械が人間並の言語能力を獲得したとしても、それだけで優れた「知性」を発揮するかはわかりません。機械の言語能力の獲得は、機械が正しいことを言うことを意味するものではありません。ただ、言語能力なしには、優れた知性に成長することはできないと考えています。
その意味では、機械の言語能力の獲得をAI技術の重要な到達点と考えることは、大きな意味を持っていると考えています。
理論の歴史が示すもの −− embedding概念の発見とその意味
人工知能の技術にも、短いながら歴史があります。その技術の歴史を貫いて、理論の歴史があります。今回のセミナーでは、AI技術の理論の歴史を振り返ってみたいと思います。
重要なことは、この4半世紀のAI技術の理論史は、「意味とは何か」を中心的なテーマとして、それを探究する理論の旅に他ならなかったということです。それが、今回のセミナーで展開する「意味の分散表現論」の発展史です。
機械が意味を理解させるためには、人間が意味とは何かを知らなくてはなりません。また、それを実装として機械に伝えなくてはなりません。いろんな試行錯誤があったのですが、意味を多次元のベクトル、embedding として表現するという方法に辿り着き、その応用に磨きをかけていきますます。
意味を表現するembeddingという概念の発見は、この4半世紀のAI研究の白眉だと思います。我々は、embedding という人間と機械の共通言語を獲得し、それを通じて機械と意味を通じ合うことができるようになったのです。
人間にとって、embedding は、話す聞くことばとしての音声と、書く読むことばとしての文字に次ぐ、ことばの第三の形態だと僕は考えています。
次回のセミナーで扱うこと
残念ながら、今回のセミナーでは、このembeddingの獲得が、情報の世界でどのようなインパクトを持つかは十分に語ることができません。
それについては、冒頭に述べたように、次回のセミナーは「embeddingの共有・蓄積・検索の未来」として展開したいと思っています。
関連コンテンツへのアクセス
- 「機械の言語能力の獲得を考える」セミナーの申し込みページ
- 「機械の言語能力の獲得を考える」セミナーのまとめページ
- 「機械の言語能力の獲得を考える」ショートムービー再生リスト
- 「機械の言語能力の獲得を考える」 blogリスト
Part 1 意味の分散表現の系譜
Bengio 「次元の呪い」
Hinton Autoencoder / 意味的ハッシング
意味の分散表現論の登場
↑↓ 見出し/画像クリックでblogへ
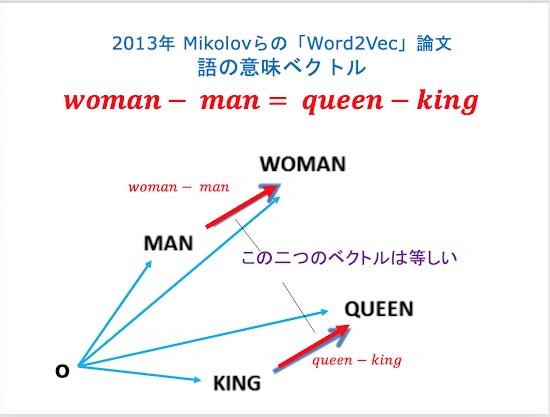
文の意味のベクトル表現の発見
↑↓ 見出し/画像クリックでblogへ
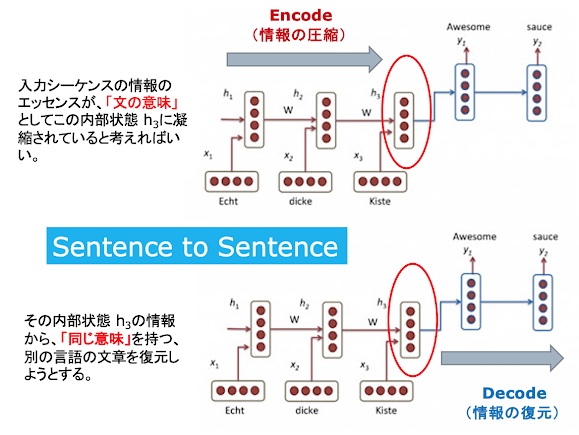
Transformerの登場
↑↓ 見出し/画像クリックでblogへ
Part 2 翻訳モデルから大規模言語モデル LLM への進化
Transformerの登場と成功は、AI技術と意味の分散表現論の大きな飛躍でした。このPart 2では、AI技術と意味の分散表現論のさらに大きな飛躍、翻訳モデルから大規模言語モデルへの移行という現代のAI技術に直接つながる重要な進化を取り上げます。
翻訳モデルから大規模言語モデルへの進化 LLM 概要 (音声概要)
↑ 見出しクリックでpdfへ
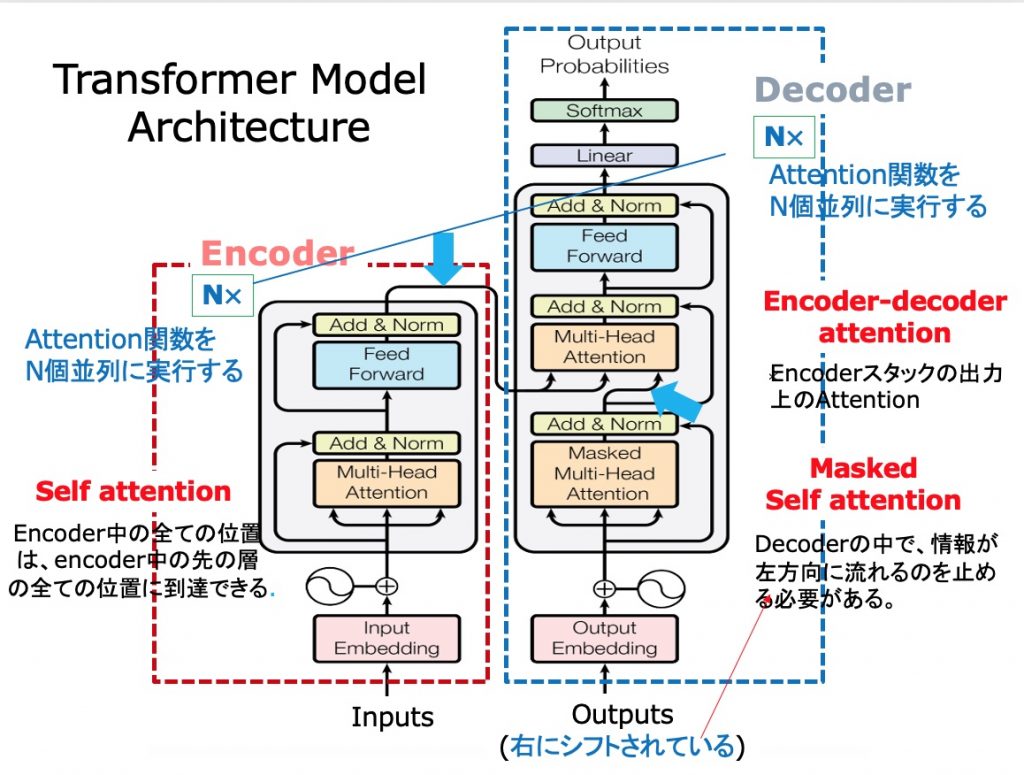
TransformerからBERTとGPTへ
翻訳モデルから大規模言語モデルへの進化の過程において、Transformerの影響は決定的なものでした。大規模言語モデルへの進化において大きな役割を果たした、Post Transformer の代表的な二つのアーキテクチャー BERTとGPTの末尾の ‘T’ がTransfomerの ‘T’ であることは、その影響の大きさを表しています。
BERT : Bidirectional Encoder Representations from Transformers
GPT : Generative pre-trained transformer
TransfomerのEncoderとDecoderの分離とその継承
ただ、Transformerの達成した成果をどのように継承するのかという点で、BERTとGPTのとったアプローチは真逆と言っていい対照的なものでした。両者は、Transformerの二つの基本的な構成要素 EncoderとDecoderを分離し、その一方だけを継承したのです。
BERT : TransformerからEncoderのみを継承。Encoder−only アーキテクチャー
GPT : TransformerからDecoderのみを継承。Decoder−only アーキテクチャー
Encoder−only, Decoder−onlyのアーキテクチャーの特徴
Transformerは、翻訳システムとして実装されていたのですが、BERTもGPTも、もはやかつてのようなSequence to Sequenceの翻訳システムではありませんでした。AIから見れば「翻訳」というのは、AIが自然言語に対して行いうる可能な仕事の一つに過ぎません。翻訳モデルの解体とより一般的なAIのモデルの模索がはじまったのです。
それでは、Encoder−only, Decoder−onlyのアーキテクチャーは、どのような特徴を持っていたのでしょう?
BERT : Encoder−only アーキテクチャー : 言語の意味の深い理解能力
GPT : Decoder−only アーキテクチャー : 言語の自由な生成能力
Decoder−onlyアーキテクチャーの勝利としての大規模言語モデル LLM の成立
重要なことは、Transformerから分岐した二つのAIアーキテクチャーのうち、Decoder−onlyアーキテクチャーの勝利として、大規模言語モデルが成立したということです。
なぜ、Decoder−onlyアーキテクチャーが勝利したかについては、この概要ではなく、別のセッションで解説したいと思います。そこでの議論は、現在の大規模言語モデルの特徴をよりよく理解するために重要な情報が含まれています。
補足情報 (音声概要)
概要とはいえ、少し情報が少ないので、次の二つの音声概要にアクセスしていただけますか?
このほかに、まだ、整理されていないのですが(ごめんなさい)、いろんな切り口で音声概要を作ってみました。、興味がありましたら、こちらもご利用ください。
Part 3 LLM アーキテクチャーの成功を支えたもの
Next token Prediction
↑ 見出しクリックでpdfへ
Self-Supervised Learning
↑ 見出しクリックでpdfへ
In-Context learningとRetrieval-Augmented Generation
↑ 見出しクリックでpdfへ

