RNN と LSTMの基礎 — Sequence to Sequence —

2017/02/22 マルレク 「RNN と LSTMの基礎」
RNNは、時系列データや自然言語のテキストのようなシーケンシャルなデータを、別の時系列データや別の言語のテキストのような、同じくシーケンシャルなデータに変換する時によく使われるニューラル・ネットワークのモデルです。
講演では、まず、これまで取り上げたFull Connectのニューラル・ネットワーク(入力も出力も「順序」を持たない)や、Convolutional ニューラル・ネットワーク(時間のない空間的な配置から特徴を抽出する)との対比で、ネットワークがループを持つRNNの特徴を述べたいと思います。
講演では、最もよく使われているRNNのモデルであるLSTM(Long Short Term Memory)にフォーカスして、RNNの基礎を解説したいと思います。
講演動画
はじめに
科学でも技術でも、その発展には、飛躍がある。もちろん、飛躍にも小さいものから大きいものまでいろいろあるのだが。面白いことに、何かが共鳴するように、いろんな飛躍が、ある時期に集中して起きることがある。
人工知能の分野では、2012年がそうした時期であった。ImageNetの画像認識の国際的コンテストで、CNNを使ったAlexNetが圧勝し、Googleの巨大なシステム DistBeliefが、教師なしでも猫の認識に成功する。それが、2012年だ。
今また、2012年のブレークスルーに匹敵する目覚ましい飛躍が、AIの世界で起きようとしている。昨年11月にサービスが始まった、Googleの「ニューラル機械翻訳」がそのさきがけである。そこで使われている技術は、RNN/LSTMと呼ばれるものである。
Googleの新しい機械翻訳のシステムは、LSTMのお化けのような巨大なシステムなのだが、 RNN/LSTMの基本原理を理解することは、誰にでもできると思う。また、そうした理解が、新しいAI技術にキャッチアップしようとするIT技術者には、必要だと考えている。
今回は、図を多用した。IT技術者の中で、 RNN/LSTM の基礎の理解が進むことを願っている。
Part I RNNの驚くべき能力について
ここでは、次のようなトピックについて述べる。 いずれも、RNNの驚くべき能力を示している。
・機械が学習・理解できることの拡大
・RNNの能力について Sepp Hochreiter
・RNNによる文の生成 Ilya Sutskever
・RNNの驚くべき能力 Andrej Karpathy
どの例も驚くべきものだが、Ilya Sutskever の実験の開いた道は、彼自身の手による機械翻訳への応用を経て、Googleニューラル翻訳技術に合流し、それから現代の「大規模言語モデル」へと発展する。
Chomskyの言語理論とGoogle機械翻訳
形式的言語の形式的文法は、つぎのような階層をなすことが知られている。これをChomsky Hierarchyと呼ぶ。
機械が、この階層の中に位置付けられるどの形式的な文法を理解・学習できたかを考えることができる。
感覚的には明らかなのだが、Google翻訳が実現した「飛躍」が、どのようなものかを正確に述べるのは、意外と難しい。翻訳の評価でよく利用されるBLEU等のスコアは、翻訳改善の重要な目安にはなるのだが、それは、あくまで量的なものだ。質的な「飛躍」は、その数字には、間接的にしか反映していない。
ここでは、英語と日本語の文法の差異に注目して、その差異が、Google翻訳では、どのように埋められているかを、いくつかの具体例で見てみよう。それらは、日本語・英語翻訳の中心的課題であるにもかかわらず、以前の機械翻訳技術では、うまく扱えなかったものである。
英語と日本語の文法の差異については、Chomskyの以前の”Principles and Parameters” 理論を援用した。
Google ニューラル機械翻訳の登場
画像認識でのCNNの成果は、誰の目にもわかりやすいものであったのだが、それと比べると、RNNの利用の成果は、直感的にはわかりにくいかもしれない。
ただ、この点で、誰もが納得できる画期的な前進があった。昨年11月に登場した、Googleの「ニューラル機械翻訳」が、それである。
Part II RNNとは何か
ここでは、次のようなトピックスを取り上げています。
次章の「LSTMの基礎」の基礎になりますので、pdf資料を参照しながら、ゆっくりご覧ください。
・RNNは、どう作られるか?
・RNNをグラフで表す– 展開形と再帰形
・Sequence to Sequence
・RNNでの φ ( WX + b ) の応用
・20数年前、いったん放棄されたRNN
・RNNの復活
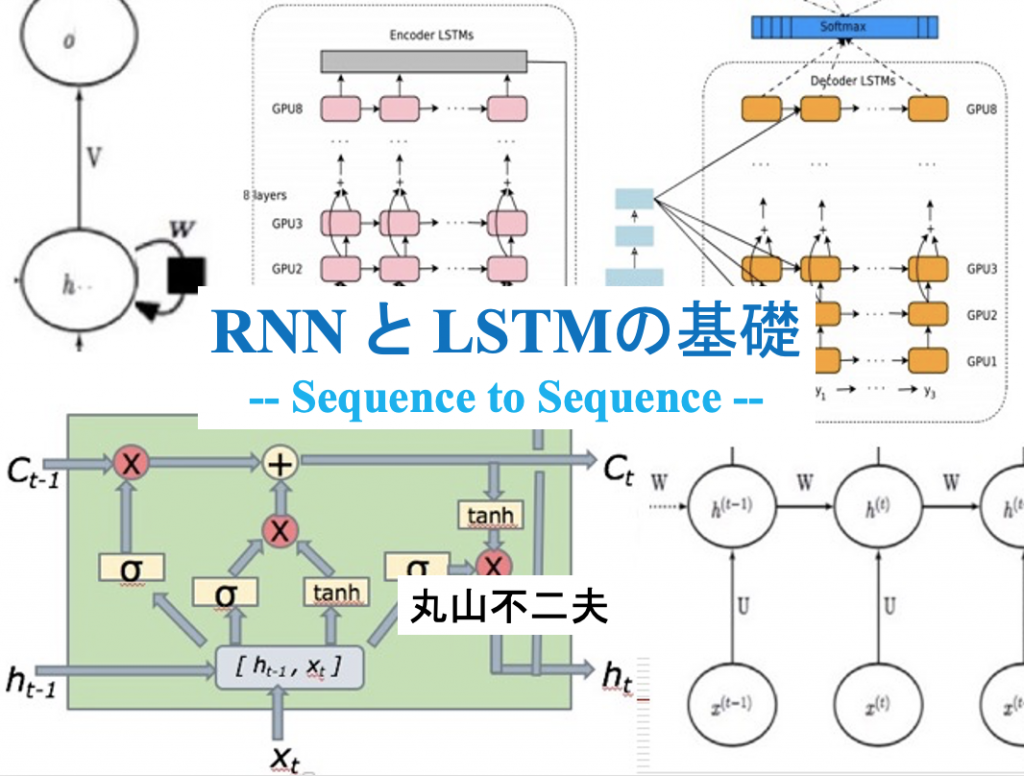
Sequence to Sequence
ここでは、RNNがなぜ “Sequence to Sequence” のNeural Network と呼ばれるのかを説明しようと思う。
入力と状態の変化が、時間上で起きると考えるのは自然である。先の図でも、添え字に用いられている (t-1) -> (t) -> (t+1) は、時間の変化に対応していると考えることもできる。ただ、本当に重要なことは、この変化が、あとさきの「順序」を持って継起することである。時間は、順序を持つ継起の一つの身近な例にすぎない。
こうして、RNNは、順番を持つ入力 x1, x2, x3, …. を、出力 o1, o2, o3, … に変換するのだが、この出力 o1, o2, o3, … も、当然、順番を持ち、順番を保つ。Sequence x1, x2, x3, …. は、Sequence o1, o2, o3, … に変換されることになる。
RNNでの φ ( WX + b ) の応用
フルコネクトのニューラルネットのある層の出力は、φ ( WX + b ) という形で表せる。
ここにφ は、その層の活性化関数、W はその層の重み、b はその層のバイアス、X はその層への入力である。
この計算式 φ ( WX + b ) は、とても基本的なものである。
この基本式が、RNNでどのように利用されているのかみておこう。
Part III LSTMの基礎
Part III — LSTMの基礎 では、次のようなトピックスを取り上げます。
・LSTMをRNNと比較する
・LSTMは「記憶」を持つ
・LSTMの振る舞いを可視化する
・LSTM — Gateを持つRNN
・LSTMの構成を、別のスタイルで概観する
・LSTMの働きを詳細に見る
・Input Unit と Input Gateの働き
・Memory Unit と Forget Gateの働き
・Status Unit とOutput Gateの働き
・LSTM の働きを式で表す(まとめ)
LSTMは記憶を持つ
ここでは、LSTMが、「記憶」を持つことを述べようと思う。
LSTMでは、RNNに新たに追加された Ct ユニットが、「記憶」を担う。これを Memory Cell と呼ぶことがある。(小論では、Memory Unit と呼んでいる)
かつて放棄されたRNNは、長い「記憶」を持つことができなかった。その主な理由は、RNNの状態が、毎ステップごとに、ループの重みWによって書き換えられるからである。
LSTMでは、Memory Cellのループの重みを1に固定する。このループは、Back Propagationによって学習される重みを持たないと考えればいい。これによって、何回ループを回っても、Memory Cell は書き換えられることがなくなる。「記憶」は、持続する。これをConstant Error Carouselという。
LSTMでの、もう一つの工夫は、ループの途中に、前の記憶を「忘れる」装置を取り付けたことだ。これを Forget Gate と呼ぶ。これは、ある時には、ループの重みがゼロになることに相当する。
これによって、LSTMは、前の「記憶」を忘れるだけでなく、新しい「記憶」に、「記憶」を更新できるようになった。
LSTMが記憶を持つニューロンとしてどのような振る舞いをするのかは、「oLSTMの振る舞いを可視化する」のセクションを、ぜひ読んでほしい。
LSTM — Gateを持つRNN
RNNは、基本的には、単純な三層構造を持つネットワークをユニットとして、その隣り合う隠れ層同士をフルコネクトで横につなげたものだ。ただし、Feed ForwardのDNNのように、実際に、ユニットを積み重ねるのではなく、隠れ層を結合する重みのパラメーターを共有し、再帰的にシステムを記述する。
RNNの発展系LSTMも、こうしたRNNの基本的なアイデアを踏襲している。ただ、組み合わせの基本となるユニットが少し複雑な構成をしている。LSTMのユニットに導入された新しいアイデアの中心にあるのが、今回、取り上げるGateである。
LSTMの働きを理解するのに、Gateの働きの理解は必須であるのだが、同時に、それは、LSTMの働きを理解する、最も早い近道でもある。
LSTMの各Unitと各Gateの働きを見る
LSTMを構成するのは、次の三つのGateである。
Input Gate:入力 xt と前の層の状態 ht-1 から、この情報をMemory Unitに渡すか否かをコントロールする。
Forget Gate :入力 xt と前の層の状態 ht-1 から、 前の層の記憶 Ct-1 を、Memory Unitに渡すか否かをコントロールする。
Output Gate:入力 xt と前の層の状態 ht-1 から、生成・更新された状態 ht を出力するか否かをコントロールする。
ここでは、まず、Input Unit での Input Gateの働きを見る。
続いて、Memory UnitでのMemory Gateの働きを見る。
LSTMの各Unitと各Gateの働きを見る 2
ここでは、Status Unit でのOutput Gateの働きを見る。
最後の「LSTM の働きを式で表す(まとめ) 」は、しっかりとチェックしてほしい。改めて、構成図を確認するのがいいと思う。
LSTMのヴァリアント
LSTMには、いくつかのヴァリアントがある。
ここでは、そのいくつかを紹介する。
講演資料 「RNN と LSTMの基礎」
資料全体ダウンロード
Part I RNNの驚くべき能力について
- 機械が学習・理解できることの拡大
- RNNの能力について Sepp Hochreiter
- RNNによる文の生成 Ilya Sutskever
- RNNの驚くべき能力 Andrej Karpathy
- 文法の階層性 — Chomsky Hierarchyについて
- Google ニューラル機械翻訳
Part II RNNとは何か?
- RNNは、どう作られるか?
- RNNをグラフで表す– 展開形と再帰形
- Sequence to Sequence
- RNNでの φ ( WX + b ) の応用
- 20数年前、いったん放棄されたRNN
- RNNの復活
Part III LSTMの基礎
- LSTMをRNNと比較する
- LSTMは「記憶」を持つ
- LSTMの振る舞いを可視化する
- LSTM — Gateを持つRNN
- LSTMの構成を、別のスタイルで概観する
- LSTMの働きを詳細に見る
- Input Unit と Input Gateの働き
- Memory Unit と Forget Gateの働き
- Status Unit とOutput Gateの働き
- LSTM の働きを式で表す(まとめ)
Appendix 各Frameworkでの実装を見る
- TensorFlowでのLSTMの定義
- TensorFlowでのLSTMの定義(Python)
- CNTKでのLSTMの定義
- MXNetでのLSTMの定義
- TensorFlow FoldでのLSTMの記述